Prerequisites: Complete Agent Builder Overview and Nodes first.
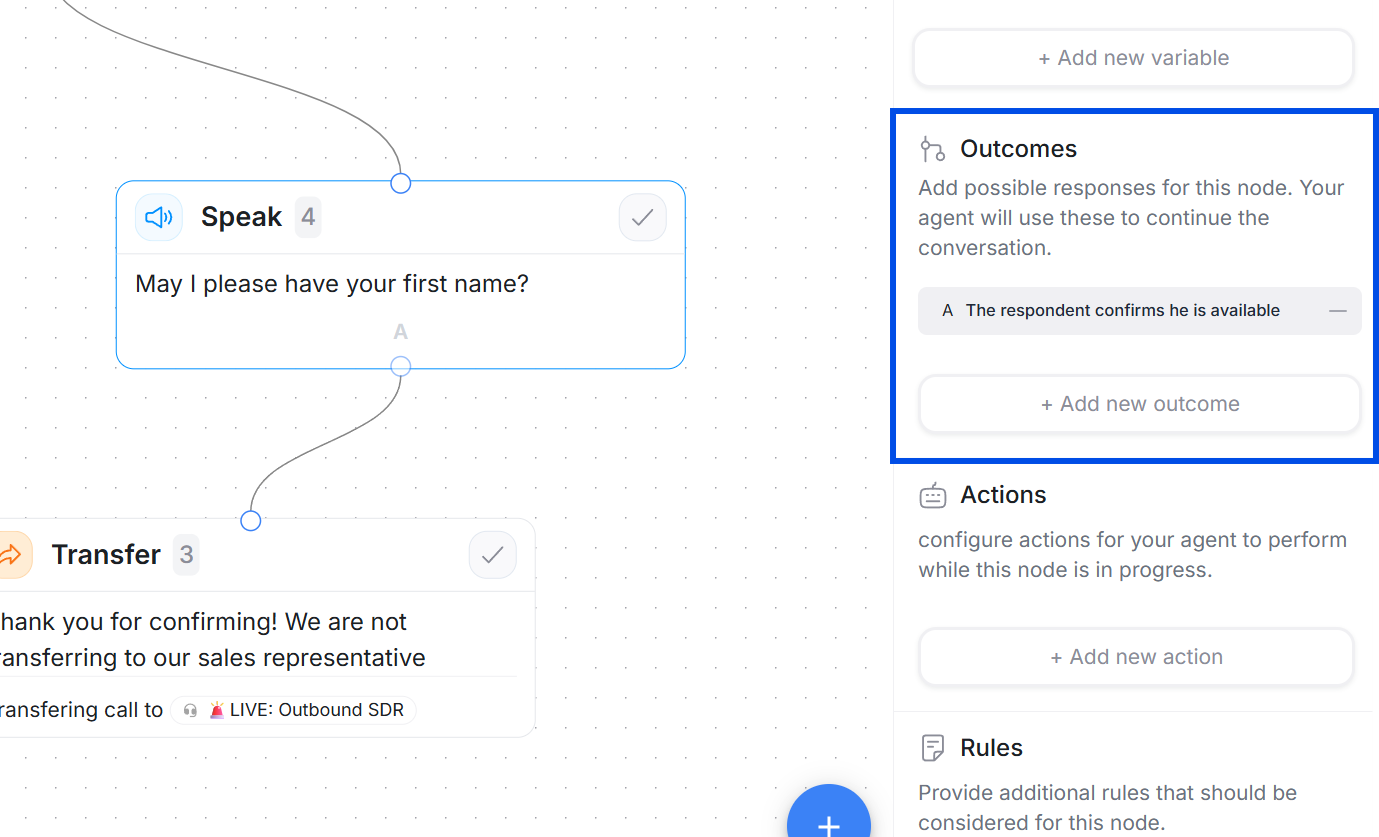
Outcome configuration panel inside a Speak node
- Prompt-based outcomes (AI decides)
- Rule-based outcomes (deterministic checks)
Comparison: Prompt-based vs Rule-based
Prompt-based outcomes (AI)
What it does: After the caller responds, Thoughtly evaluates the reply with AI and selects the best matching outcome. When to use:- Interpreting open-ended replies (interest level, objections, next-step intent)
- Handling varied phrasing where exact keywords are unpredictable
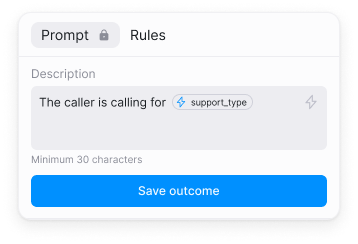
Add prompt-based outcomes
- Be distinct. Avoid overlapping labels such as “Positive” and “Very positive.”
- Be concrete. Prefer “Wants appointment” over “Positive answer.”
- Be short. Aim for 12-50 characters or one to two short sentences.
- Cover common branches. Skip tiny variations that sound the same.
- Wants to book now
- Interested, send SMS link
- Not interested
- Busy - call back later
- Draft three to five sample caller replies for each outcome.
- Run test calls or the simulator and observe which path is chosen.
- If outcomes collide, rename them to be more specific and retest.
Rule-based outcomes (deterministic)
What it does: After the caller responds (or after an Action runs), the system checks your rules from top to bottom and takes the first match. No AI is involved. When to use:- Branching based on structured info (yes/no answers, numbers, captured email)
- Navigating after Actions (lookup results, API flags, form validation)
- Enforcing critical logic where ambiguity is risky (compliance, verification, eligibility)
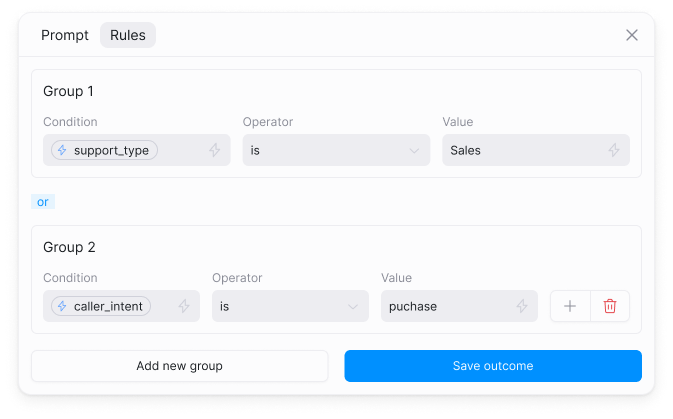
Rule evaluation order
- Outcomes are checked from top to bottom in the order you arrange them
- The first matching rule wins and routes to its connected node
- All subsequent rules are skipped once a match is found
- Always add a final Else (default) outcome to catch anything that doesn’t match
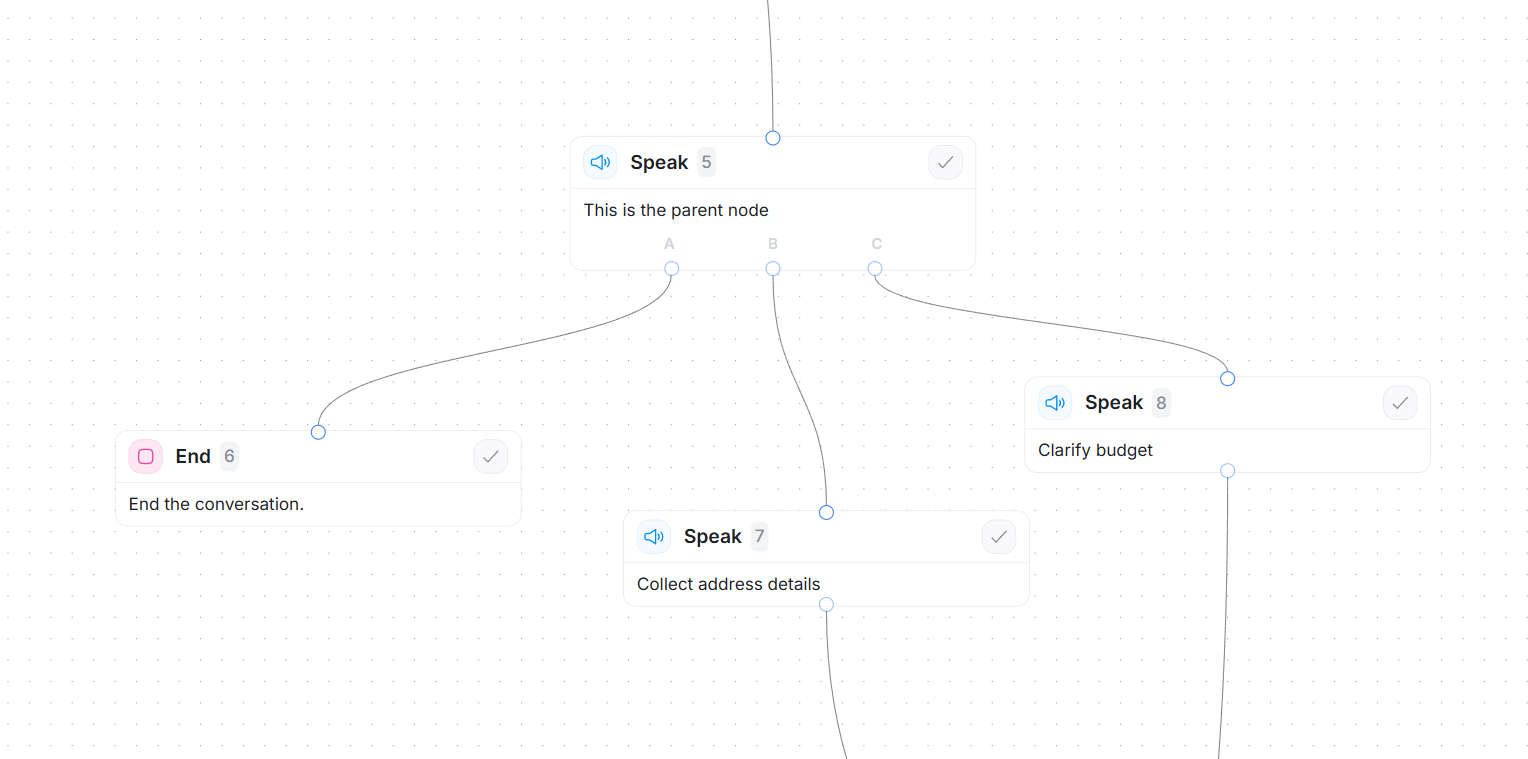
Rule-based outcomes flow with A, B, C paths
Outcome A (checked first)
Rule:
→ Routes to: End node (conversation terminates)Outcome B (checked second, only if A fails)
Rule:
→ Routes to: Collect address details (next step in happy path)Outcome C (checked third, acts as Else/Default)
Rule: Always matches if A and B both failed
→ Routes to: Clarify budget (fallback to gather more info)
Rule:
caller_said_stop == true→ Routes to: End node (conversation terminates)Outcome B (checked second, only if A fails)
Rule:
email_is_valid == true→ Routes to: Collect address details (next step in happy path)Outcome C (checked third, acts as Else/Default)
Rule: Always matches if A and B both failed
→ Routes to: Clarify budget (fallback to gather more info)
- Are rules mutually exclusive where needed?
- Is the most specific rule above the general ones?
- Do you have a final Else/Default outcome?
- Did you test negative and no-input cases?
Loops (special use case)
You can loop an outcome back to the same node.- Keep answering questions until the caller is satisfied.
- Re-ask or verify required information such as email or budget.
- Speak node -> Prompt: “Answer the caller’s questions clearly and concisely. If the caller asks a new question, continue; if not, proceed.”
- Add two prompt-based outcomes:
- Caller asked a question -> connect back to this node (self-loop)
- No more questions -> go to the next step
- Test with varied phrasing to confirm the loop works.
Troubleshooting
Outcomes not triggering correctly- Verify outcome type matches your use case (prompt for open-ended, rules for structured)
- Check that outcome labels are distinct and specific
- Test with varied caller responses using Test Agent
- Ensure rule-based outcomes have an Else/Default path
- Verify all conditions are achievable (not logically impossible)
- Check that prompt outcomes have at least 2-3 options
- Rename outcomes to be more specific and concrete
- Add more example phrases in your testing
- Consider switching to rule-based if logic is too complex
- Remember: first match wins in rule-based outcomes
- Move specific rules above general ones
- Test all branches with Test Agent
Common mistakes to avoid
- Vague labels: Using “Positive” instead of “Wants to book now” in prompt mode
- Missing Else: Forgetting the default fallback in rule-based outcomes creates dead ends
- Wrong order: Placing general rules before specific ones causes incorrect matches
- Compliance risk: Using prompt outcomes for legal/medical/financial decisions where exactness matters
See also
- Speak nodes - choose Message vs. Prompt
- Actions - mid-call steps that set flags and values
- Variables - capture data for branching logic
- Transfer node - escalate to humans or other agents
- End node - finish conversations cleanly
- Testing - validate outcome logic with Test Agent
- Glossary: Happy Path - designing the ideal conversation flow
Variables
Capture caller data and reuse it in your flows ->